At ITP camp, I attended a workshop by Orren Ravid entitled Maths as a Spoken Language. Orren discussed methods for representing creative expressions of thought with equations. We looked at an example of how to use a representation to quantify emotion.
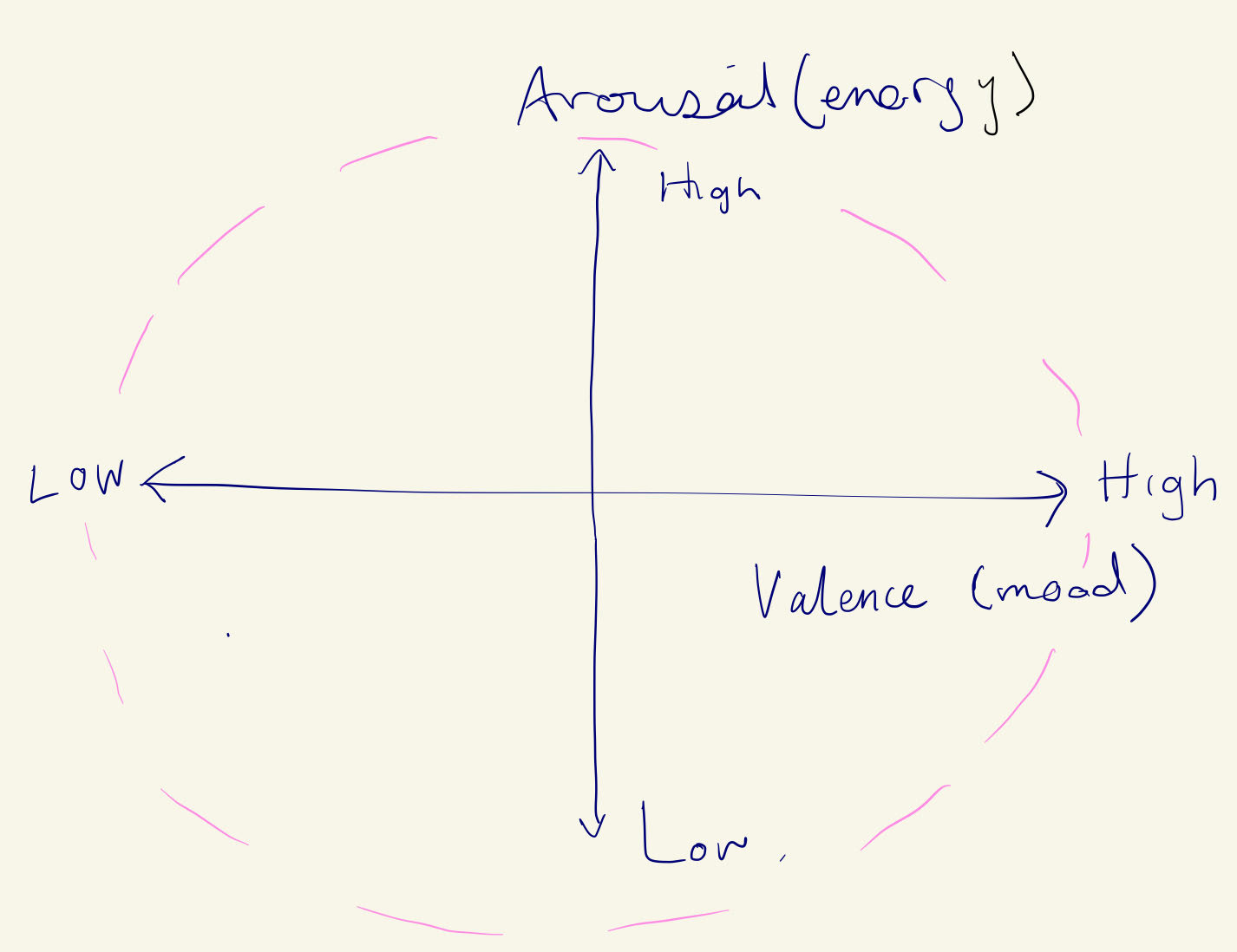
Figure 1 is a rough drawing of the polar coordinates system we looked at as an example. It defines arousal (energy level) on the Y axis from low to high and valance (mood) from sad to happy. Within this system, a breadth of emotions can be represented by coordinates; for example, high arousal and low valence could be anger. While this simple representation can not capture the full range of human emotion, it is a starting point. By adding time (or change in time), we animate the mood and develop a language of change; the rate of change in mood over time can be considered as “mood speed”.
The idea of a “mood speed” is particularly relevant to Flow, a project I am working on in collaboration with the artist Georgie Pinn. Flow is an interactive audiovisual artwork that encourages connection between participants and exploration of emotions through the metaphor of water. Flow will respond to expressive input from the audience, who can interact with sound and visual elements through movements and touch.
I have been considering the parameters required to measure and respond to audience actions, creating experiments in Touchdesigner, the primary software we will use for this project. I am attempting to understand what inputs we can use from the audiences’ movements and expressions and their interactions with each other.
What can we measure to capture emotion?
Experiment: Facial expressions
When we initially developed the idea for this project, I had been using ML5.js, a machine learning javascript library, at the time ML5.js included expression detection as part of the FaceAPI model. Expression detection has since been removed from ML5.js due to concerns it could be used in ways that would violate their code of conduct, leading me to look for other ways to get expressive inputs from the audience.
MediaPipe TouchDesigner plugin is an open-source plugin for TouchDesigner that uses Google’s machine learning for mobile devices project – MediaPipe. It contains access to several models, allowing for pose tracking, face tracking, object detection, and image segmentation. The plugin’s face tracker uses AI to track 3D facial landmarks and can be used to identify facial expressions without explicit emotion detection.
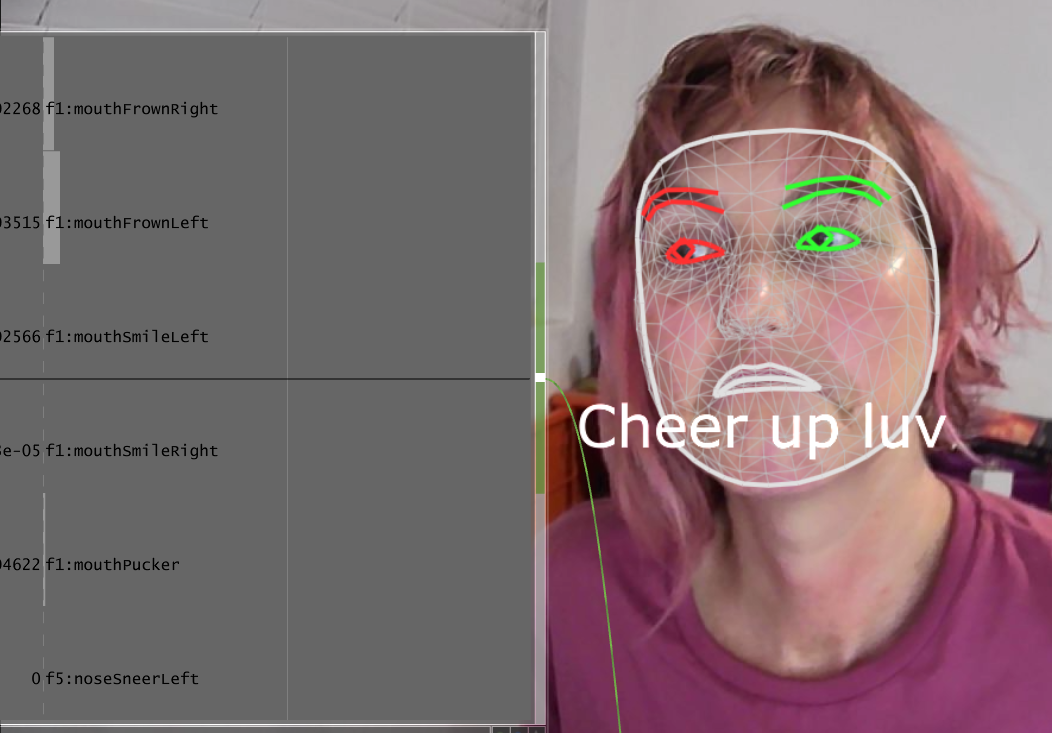
To test out some of MediaPipe plugin face tracker parameters, I created a Cheer Up Machine. A simple project that says “Cheer up luv” anytime I wasn’t smiling. A future version of this would spit out variations of the sentiment – “You’d look prettier if you smiled”, etc. I found that moving the threshold for recognition of a smile impacted the experience and ‘personality’ of the Cheer Up Machine. With a high threshold, one must smile very hard and keep smiling lest the machine tell you to cheer up. This forced cheerfulness suited the personality I was aiming to create with this experiment.
Experiment: Body Track Chop
The Body Track chop uses Nvidia processing and AI to detect bodies with a basic web camera. If the results are robust enough to suit this project, it would reduce the need for specialist sensors such as the Kinect. One advantage of the kinect is that, being a depth camera, it doesn’t require any special lighting. I downloaded a variety of videos from Pexels with people walking both alone and in groups and from a variety of angles. In Touchdesigner I set up a body tracker to recognise four different bodies, each body was represented by particles of a single colour to identify how each body was being defined. From these prerecorded video tests the Body Track Chop appears to work best with participants facing towards the camera and to have no overlapping bodies. These results should be tested in a real-life situation for further evaluation. The kinect should also be tested as an alternative camera.






Inputs to test
The following outlines ideas and questions for audience input that will be tested next.
Grouping
Another input to explore is grouping or the proximity of audience members to each other. Many people will attend the work in preformed groups that will form and disperse as they interact with the work. How can I encourage group movements where people work together to affect the sound and vision?
What constitutes a group? How will I recognise that?
Can we recognise multiple groups?
Collision Points
Could we have virtual objects for the audience to interact with on screen? Would an invisible object be a good way to measure movement and speed?
Speed of Movement
How does the audience speed in moving around the space and moving their limbs affect emotion?